

 上一篇「Node.js 爬蟲開發新手技巧﹍Google Apps Script 替代品」說明了為何我選擇 Node.js 作為爬蟲程式,並搭配 Google 試算表這個免費雲端資料庫,只要學會 Javascript 就能通吃「前端+後端+資料庫」,非常方便好上手。
閱讀本篇之前最好先瞭解上一篇的這些內容:
上一篇「Node.js 爬蟲開發新手技巧﹍Google Apps Script 替代品」說明了為何我選擇 Node.js 作為爬蟲程式,並搭配 Google 試算表這個免費雲端資料庫,只要學會 Javascript 就能通吃「前端+後端+資料庫」,非常方便好上手。
閱讀本篇之前最好先瞭解上一篇的這些內容:
- 建立 Node.js 開發環境
- 操作開發工具 Sublime Text 3
- Node.js 原生/外部模組如何引用
- 同步/非同步的概念與技巧
一、安裝 Axios、Cheerio 模組
以下分別說明兩個 Node.js 爬蟲會用到的重要模組。 1. Axios Jquery 爬取網頁資料使用的方式為 $.ajax,Google Apps Script(簡稱GAS) 爬取網頁資料使用的方式為 UrlFetchApp.fetch。而 Node.js 爬取網頁有很多模組可用,例如:- Https:原生模組,參考「https.request()用法及代碼示例」
- Request:第三方模組,參考「request是node.js中類似curl功能」
- 官網:Axios
- 教學:axios 基本使用
npm i axios -g
yarn global add axios
2. Cheerio
爬回來的網頁資料,無論是 HTML 或 XML 格式都不方便處理,此時需要一個類似 Jquery 的工具來操作 DOM 比較方便。而 Node.js 知名的「類 Jquery」第三方模組為 Cheerio:
- 官網:Cheerio
- 教學:Cheerio 教學
npm i cheerio -g
yarn global add cheerio
二、Node.js 爬蟲範例
1. 取得 HTML 資料 爬網頁 HTML 內容難度最低,使用 Cheerio 操作 DOM 會更方便(使用技巧可參考「Cheerio 輕鬆解析 HTML 與 XML 」)。 那麼就以本站 WFU BLOG 為例,如上圖,練習爬取「本站服務」區塊的文章標題及圖片,資料位於 #HTML8 之下每個 .item 裡的的 .title 及 .thumb。
那麼就以本站 WFU BLOG 為例,如上圖,練習爬取「本站服務」區塊的文章標題及圖片,資料位於 #HTML8 之下每個 .item 裡的的 .title 及 .thumb。
var axios = require("axios"),
cheerio = require("cheerio"),
url = "https://www.wfublog.com/";
axios.get(url).then(function(res) {
var data = res.data,
$ = cheerio.load(data),
title_thumb_array = [];
$("#HTML8 .item").each(function () {
var $this = $(this),
title = $this.find(".title").text(),
thumbUrl = $this.find(".thumb img").attr("src");
title_thumb_array.push([title, thumbUrl]);
});
console.log(title_thumb_array);
});
下圖為執行結果,成功!
 2. 取得 JSON 資料
如果網頁內容是用 JS 動態產生,那麼撈 HTML 資料就沒用了,此類網頁可參考「製作網路爬蟲工具抓動態產生的網頁資料」,用 Chrome 開發人員工具找出儲存資料的連結。
2. 取得 JSON 資料
如果網頁內容是用 JS 動態產生,那麼撈 HTML 資料就沒用了,此類網頁可參考「製作網路爬蟲工具抓動態產生的網頁資料」,用 Chrome 開發人員工具找出儲存資料的連結。
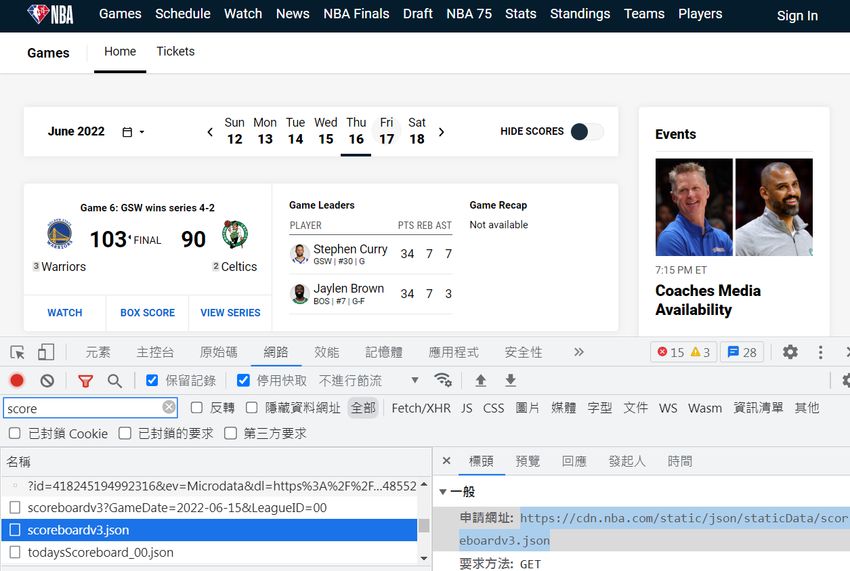 本篇同樣以 NBA 官網作為範例,找出當日的比賽結果。找出 json 檔的流程省略,如上圖,今天是總冠軍賽最後一場,勇士 4-2 獲勝,資料檔案放在 scoreboardv3.json:
本篇同樣以 NBA 官網作為範例,找出當日的比賽結果。找出 json 檔的流程省略,如上圖,今天是總冠軍賽最後一場,勇士 4-2 獲勝,資料檔案放在 scoreboardv3.json:
var axios = require("axios"),
url = "https://cdn.nba.com/static/json/staticData/scoreboardv3.json";
axios.get(url).then(function(res) {
var data = res.data,
scoreboard = data.scoreboard;
console.log(scoreboard);
});
下圖為執行結果,成功!

三、寫入資料庫
1. 寫入檔案 處理完爬蟲資料後,寫入檔案可用原生模組 fs(教學文章可參考「Node.js 檔案系統」),操作方式如下:var fs = require("fs");
fs.writeFile("檔案路徑及檔名", "檔案內容"); // 寫入檔案
fs.appendFile("檔案路徑及檔名", "新增內容"); // 新增內容至檔案
2. 寫入 Google 試算表
將資料寫入資料庫可以有更多的應用方式及情境,例如寫入 Google 試算表,可以隨時從網路存取非常方便,這部分的操作可參考「用 Google Apps Script 操作 Google 試算表」系列文章。
四、Windows 自動執行程式
以前使用 GAS 可以設定自動排程,Google 會自動在雲端幫我們執行,不會有忘記的時候,但缺點如前一篇所提,每次最多只能執行 6 分鐘。 如果 Node.js 爬蟲任務需要每天定時撈資料並自動處理後續,有兩種作法: 1. Node.js 排程模組 可參考「node-schedule模塊的使用」,安裝 node-schedule 這個第三方模組來進行設定。 這個方法適合已經執行 Node.js 以後,再呼叫模組來進行排程,也等於是半手動排程,不適合機械化執行。 2. Windows 排程 如果想要電腦開機後,每天設定的時段一到自動執行,可利用 Windows 內建的排程工具,參考「如何設定工作排程」,以 Win7 為例:- 按
Win+R → taskschd.msc → 可開啟工作排程器 - 建立基本工作 → 填入名稱 → 設定執行頻率 → 設定開始時間 → 啟動程式
- 「瀏覽」後找出、或填入 node.exe 完整路徑 →「新增引數」填入要執行的 js 檔名 →「開始位置」填入這個 js 檔的路徑
- 之後「下一步」到完成即可
更多「爬蟲」相關技巧:




沒有留言:
張貼留言注意事項:
◎ 勾選「通知我」可收到後續回覆的mail!
◎ 請在相關文章留言,與文章無關的主題可至「Blogger 社團」提問。
◎ 請避免使用 Safari 瀏覽器,否則無法登入 Google 帳號留言(只能匿名留言)!
◎ 提問若無法提供足夠的資訊供判斷,可能會被無視。建議先參考這篇「Blogger 提問技巧及注意事項」。
◎ CSS 相關問題非免費諮詢,建議使用「Chrome 開發人員工具」尋找答案。
◎ 手機版相關問題請參考「Blogger 行動版範本的特質」→「三、行動版範本不一定能執行網頁版工具」;或參考「Blogger 行動版範本修改技巧 」,或本站 Blogger 行動版標籤相關文章。
◎ 非官方範本問題、或貴站為商業網站,請參考「Blogger 免費諮詢 + 付費諮詢」
◎ 若是使用官方 RWD 範本,請參考「Blogger 推出全新自適應 RWD 官方範本及佈景主題」→ 不建議對範本進行修改!
◎ 若留言要輸入語法,"<"、">"這兩個符號請用其他符號代替,否則語法會消失!
◎ 為了過濾垃圾留言,所有留言不會即時發佈,請稍待片刻。
◎ 本站「已關閉自刪留言功能」。